Question
How does mutual information between tokens decay with distance across typologically diverse languages, and does language structure (morphology, word order) shape the information topology?
Setup
Pure IT analysis of raw Bible text (JHU corpus), 5 languages (en/pt/tr/fi/ar). NO model. v3: full vocab (12K-56K), corpus equalized to 435K tokens, trapezoidal MI budget, 10 shuffles for bias floor, log-log/log-linear R², surprisal normalized by H(unigram), per-genre on subsampled data, 5-seed subsample sensitivity. ~25 min CPU.
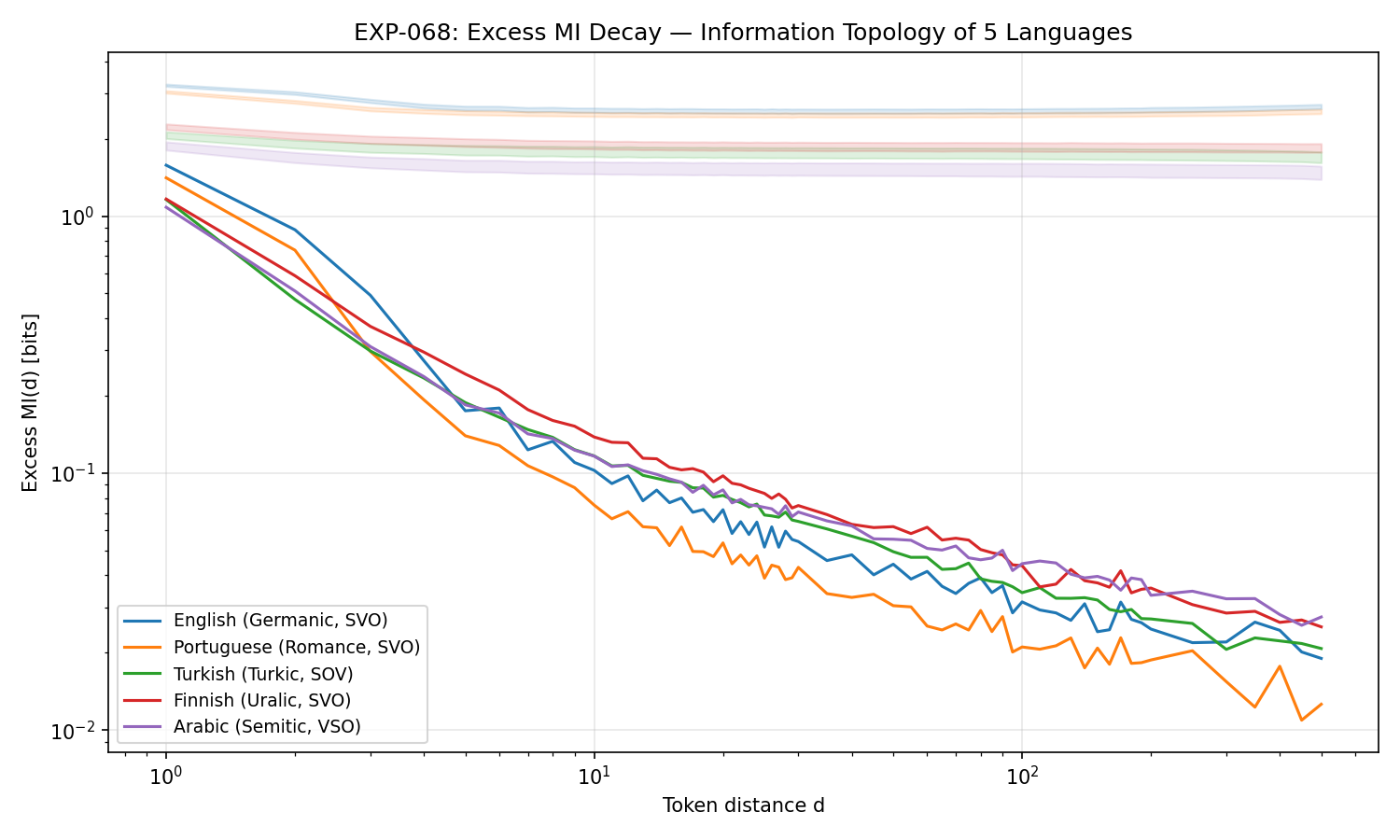
Excess MI decay (log-log). All 5 languages show clean power-law decay (R²>0.96). Analytic languages (en/pt) decay slower (β≈1.1-1.2) than agglutinative (tr/fi/ar, β≈0.87-0.98), suggesting morphology shapes how far information propagates.
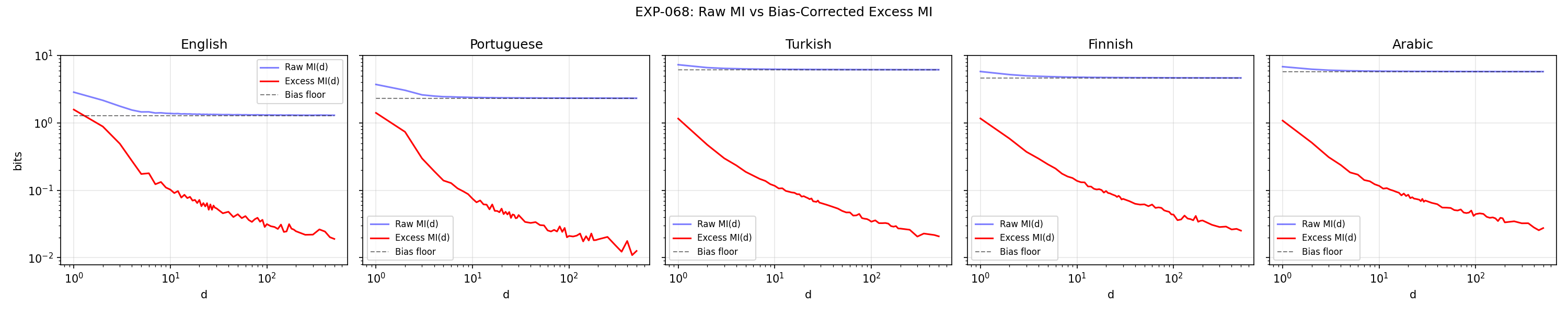
Raw MI vs bias-corrected. Shuffle-based bias correction (10 shuffles) removes the finite-sample floor that inflates raw MI at long distances. Essential for trustworthy long-range estimates, especially with large vocabularies (12K-56K).
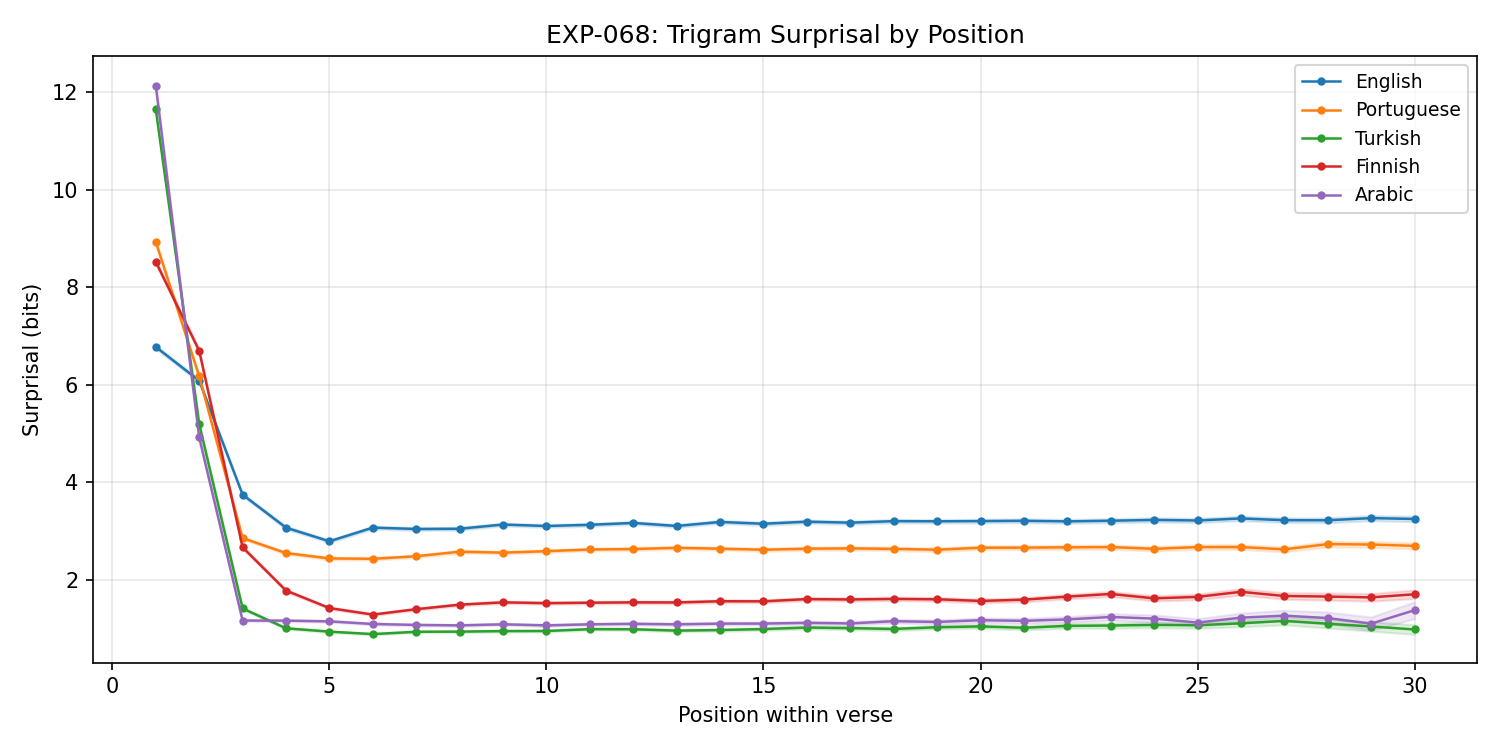
Trigram surprisal by verse position. Surprisal normalized by H(unigram) reveals Arabic's high raw surprisal is entirely vocab size (S/H=1.00), while Finnish shows strongest initial context (S/H=0.75) from morphological agreement.
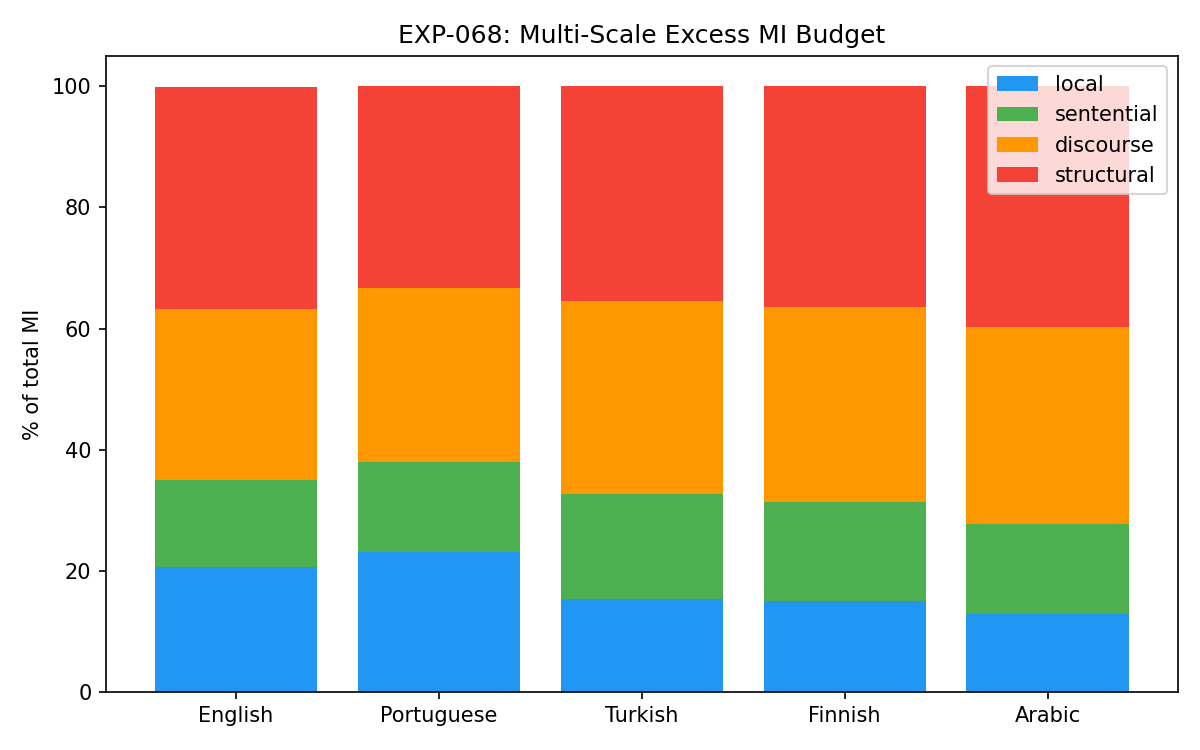
Multi-scale MI budget. Trapezoidal integration splits MI into local (1-10), sentential (11-200), and structural (201-500) bands. Structural share is 33-40% by area, but absolute ExMI at d>200 is only 0.02-0.04 bits, near noise floor. Arabic has highest discourse share (39.7%).
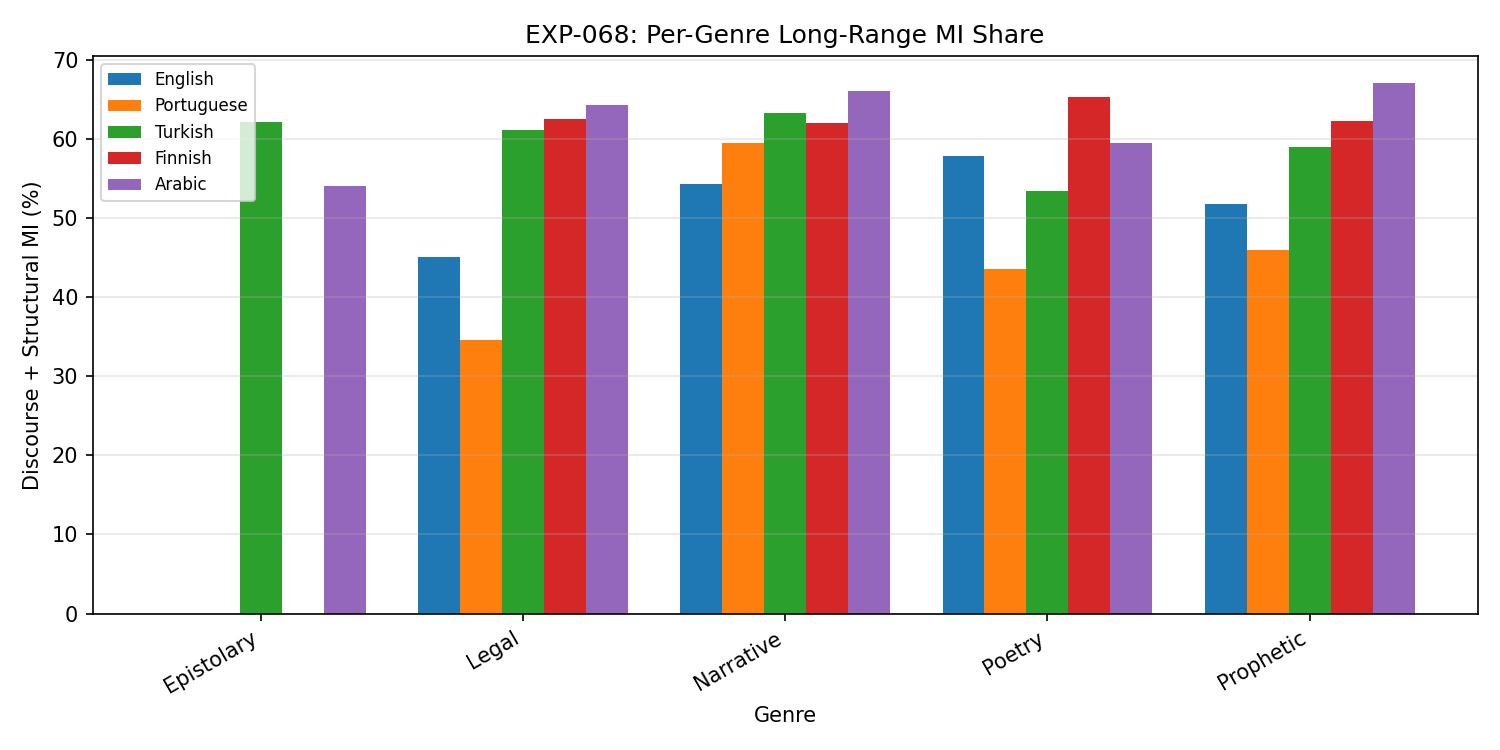
Per-genre discourse MI share. Narrative consistently has the highest discourse MI (54-66%) across all languages; epistolary the lowest. Genre distribution in training data matters for architecture evaluation.
Results
| Lang | ExMI(1) | PL beta | beta 95% CI | PL R² | Local% | Structural% | S(1)/H |
|---|---|---|---|---|---|---|---|
| en | 1.577 | 1.118 | [0.742, 1.369] | 0.981 | 20.7% | 36.6% | 0.79 |
| pt | 1.409 | 1.234 | [0.742, 1.554] | 0.982 | 23.1% | 33.3% | 0.94 |
| tr | 1.159 | 0.981 | [0.583, 1.036] | 0.969 | 15.4% | 35.5% | 0.93 |
| fi | 1.165 | 0.872 | [0.614, 0.900] | 0.981 | 15.0% | 36.4% | 0.75 |
| ar | 1.082 | 0.919 | [0.527, 0.963] | 0.966 | 12.8% | 39.7% | 1.00 |
Key findings
- Power-law MI decay universal (5/5 langs, R²>0.96). Exponential catastrophically fails in log-linear R² (<-10). SSM exponential kernels are structurally mismatched.
- Beta exponent descriptively splits by morphology: analytic (en/pt) 1.1-1.2 vs agglutinative (tr/fi/ar) 0.87-0.98. CIs overlap (wide from curve-fit resampling) but subsample seed variance (std 0.003-0.057) is 3-6x smaller than between-group differences.
- Trapezoidal MI budget: structural (201-500) = 33-40% by area, but ExMI at d>200 is only 0.02-0.04 bits — near noise floor. Local vs sentential split is more trustworthy.
- Arabic S(1)/H(unigram) = 1.00 — high raw surprisal is entirely vocab size, not word order (though trigram sparsity at V=55K may contribute). Finnish S/H=0.75 = strongest initial context, from morphological agreement.
- Narrative genre has highest discourse MI across all languages (54-66%); epistolary lowest. Genre distribution matters for architecture evaluation.
- Subsample seed sensitivity confirms stability: ExMI std 0.003-0.052, beta std 0.003-0.057 across 5 seeds.
Lesson learned
Trapezoidal integration for MI budget is essential with non-uniform distance sampling. Naive sums drastically overweight the densely-sampled local range. Shuffled MI control is powerful enough to handle full vocabularies (12K-56K) without truncation. Surprisal normalization by H(unigram) completely changes the word-order story: Arabic's "high surprise" is just vocab size. Curve-fit bootstrap CIs on beta are too wide to be useful; subsample seed sensitivity is a better complementary measure. Structural-distance MI (d>200) is near the noise floor even with 10 shuffles, so claims about long-range MI should focus on d<200 where signal is clean. Per-genre analysis on subsampled data loses some genres entirely due to contiguous block selection; verse-level subsampling would preserve genre coverage better.
Known limitation: word-level tokenization confound. The morphology/exponent split (analytic β≈1.1-1.2 vs agglutinative β≈0.87-0.98) may be partially an artifact of token granularity. A single word in agglutinative languages (e.g. Turkish "evlerimizdekilerden") encodes what would be 5-6 tokens in English, so between-token MI in agglutinative languages has already "absorbed" dependencies that would span multiple tokens in analytic ones. This could make the decay look faster without reflecting a true structural difference. A byte-level or morpheme-level replication is needed to disentangle morphology from tokenization granularity.
Tools used
Python 3.10, NumPy, SciPy (curve_fit), Matplotlib. JHU Bible Corpus XML. No GPU needed. Claude Code for autonomous development and debugging. Total compute: ~8 minutes on CPU.