Power-Law Kernel Initialization: Theory-Guided Init Gives 0.039 BPB Free at 10M Scale
@eazevedoQuestion
Does initializing a diagonal SSM's output projection to match the theoretical power-law MI decay structure (beta~1.15) improve convergence speed or final BPB over uniform initialization?
Setup
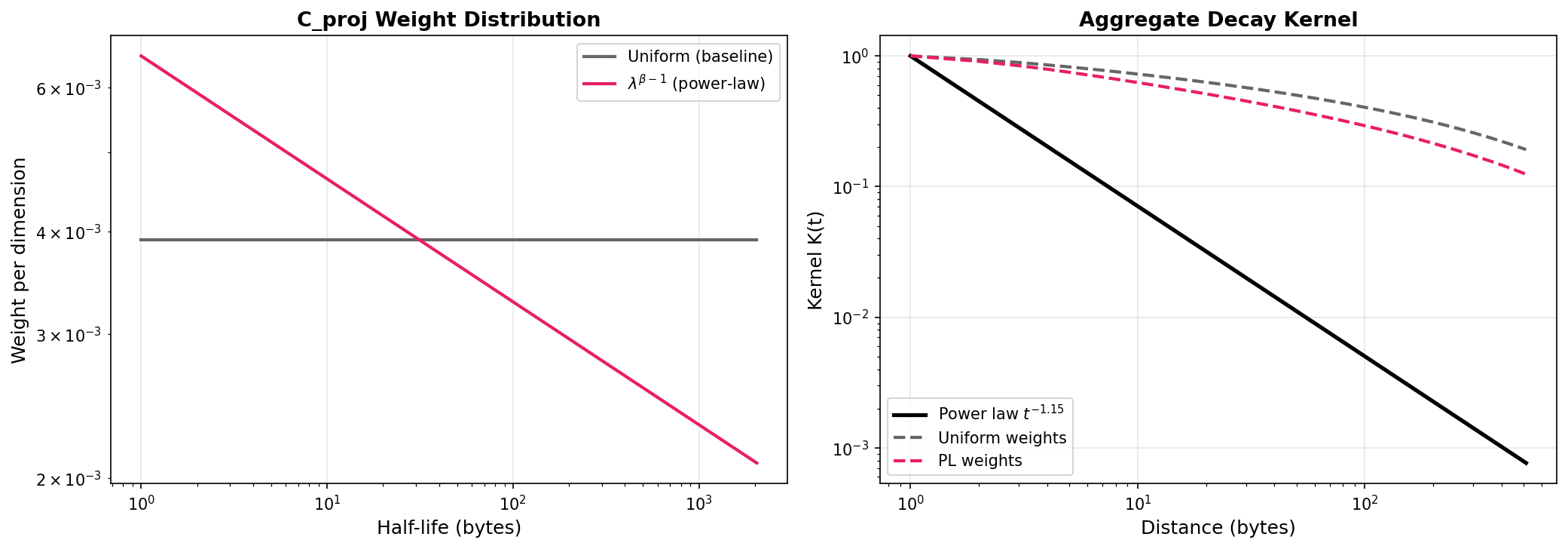
Mathematical analysis first: NNLS fitting showed 256 log-spaced exponentials with uniform weights produce R^2=-18 vs power law t^(-1.15), but with optimal weights R^2=0.9975 using only 6 active dimensions. The architecture CAN represent power-law decay; the question is whether C_proj can learn the extreme weight distribution from uniform init, or whether theory-guided init helps.
Why uniform weighting fails. Left: the theoretical power-law weight (lambda^(beta-1)) concentrates on fast-decay dimensions, while uniform init gives all dimensions equal weight. Right: the resulting aggregate kernel with uniform weights (dashed gray) decays far too slowly compared to the true power law (solid black). Power-law weights (dashed pink) match closely.
3 conditions at 10M scale (d=512, L=6, P=2 residual patching, 9.72M params), 1h each on RTX 3060 Ti 8GB, wiki_ptbr. Identical architecture, param count, optimizer (AdamW lr=3e-4, wd=0.01), and data across all conditions.
Condition 1 (Baseline): Log-decay init (half-lives 1-2000 bytes, log-spaced) + uniform C_proj init (normal(0, 0.02)).
Condition 2 (PL C_proj): Same log-decay rates + C_proj columns scaled by lambda^(beta-1) where lambda=-log(a_i), beta=1.15, normalized by mean to preserve overall scale. Gives ~3x weight ratio between fastest and slowest decay dims.
Condition 3 (Concentrated+PL): Concentrated decay rates (40% dims near hl=1, 25% near hl=10, 20% near hl=80, 15% near hl=2000, each spread via logspace(anchor0.5, anchor2.0)) + power-law C_proj scaling. Anchor percentages were chosen to approximate the NNLS weight distribution, which found 6 active dims at half-lives {1.0, 10.0, 10.3, 81.1, 83.5, 2048.0} with 93.6% weight on hl=1.
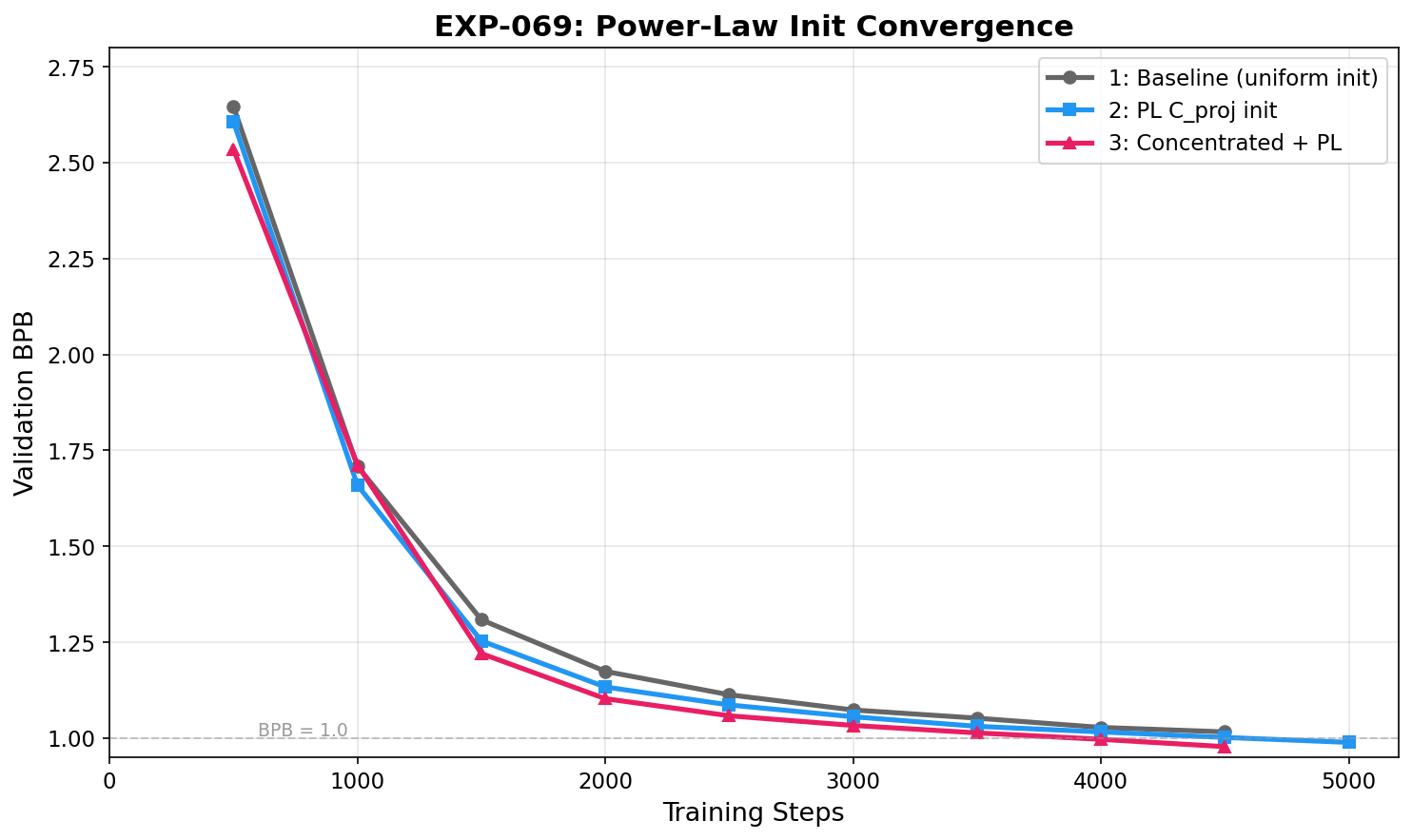
Val BPB convergence. Condition 3 (concentrated + PL) leads throughout training. The gap is largest in mid-training and stabilizes at ~0.04 BPB by the end. Neither model has converged.
BPB improvement over baseline at each checkpoint. Condition 3 gains most in early/mid training (0.07-0.11 BPB at steps 500-2000), settling to a persistent 0.04 BPB advantage. Condition 2 (C_proj only) shows a smaller but consistent gain.

N=1 per condition (no seed variance reported). Results are suggestive, not definitive. Val BPB evaluated every 500 steps.
Results
| Condition | Val BPB (best) | Val BPB (final) | Steps | Val BPB @ step 2000 | Val BPB @ step 3000 | Val BPB @ step 4000 |
|---|---|---|---|---|---|---|
| 1: Baseline | 1.0163 | 1.0127 | 4679 | 1.1741 | 1.0734 | 1.0279 |
| 2: PL C_proj | 0.9890 | 0.9874 | 5148 | 1.1334 | 1.0557 | 1.0162 |
| 3: Concentrated+PL | 0.9778 | 0.9739 | 4949 | 1.1029 | 1.0331 | 0.9969 |
Key findings
- Condition 3 (concentrated rates + PL C_proj) achieves val BPB 0.9739 vs baseline 1.0127, a 0.039 BPB improvement with zero additional parameters or per-step compute. Condition 2 (PL C_proj alone) gives 0.025 BPB gain; concentrated decay rates add another 0.014 on top.
- Convergence is consistently faster: at step 2000, Condition 3 val BPB is 1.1029 vs baseline 1.1741 (0.071 gap). At step 4000, Condition 3 is 0.9969 vs baseline 1.0279 (0.031 gap). The gap narrows over training but persists.
- Neither model has converged (training loss still dropping at experiment end). The gap could narrow or widen with longer training. Single seed per condition; results are suggestive but require multi-seed replication for confirmation.
- The NNLS analysis predicted this result: the architecture can represent power-law decay (R^2=0.9975 with optimal weights), but uniform C_proj init is 25,000% off from the optimal weight distribution. Theory-guided init closes this gap at zero per-step cost, though it requires prior knowledge of the domain's MI decay exponent (beta=1.15 from EXP-002/EXP-068).
- C_proj scaling is normalized by mean to preserve overall initialization magnitude. The effect is therefore from the shape of the weight distribution (favoring fast-decay dims), not from changing the absolute scale of C_proj.
Lesson learned
When the information-theoretic structure of data is known, encoding it in initialization is low-risk and potentially high-reward. The key mathematical insight: a sum of exponentials with uniform weights decays far too slowly to match a power law (the slow-decay dimensions dominate), but with theory-guided weights (lambda^(beta-1) scaling), even a few exponentials suffice. This is a direct consequence of the Laplace transform representation of power laws.
Methodological note: the conditions were labeled 1/2/3 in the experiment but originated from a brainstorming session where they were called A/C (with B being a multi-rate sub-state approach that was deprioritized after the NNLS analysis showed 6 dims suffice). Future work: multi-seed replication, test at 100M scale on FineWeb, and investigate whether the optimal beta varies across domains (EXP-068 showed beta ranges from 0.87 to 1.23 across languages).
Tools used
Claude Opus 4.6 via Claude Code for experiment design, mathematical analysis (NNLS fitting), and code implementation. PyTorch 2.x with custom Triton parallel scan kernel. RTX 3060 Ti 8GB. scipy.optimize.nnls for power-law approximation analysis.